NLP in Produktion: Wie PDFs im Haystack-NLP Framework verarbeitet werden
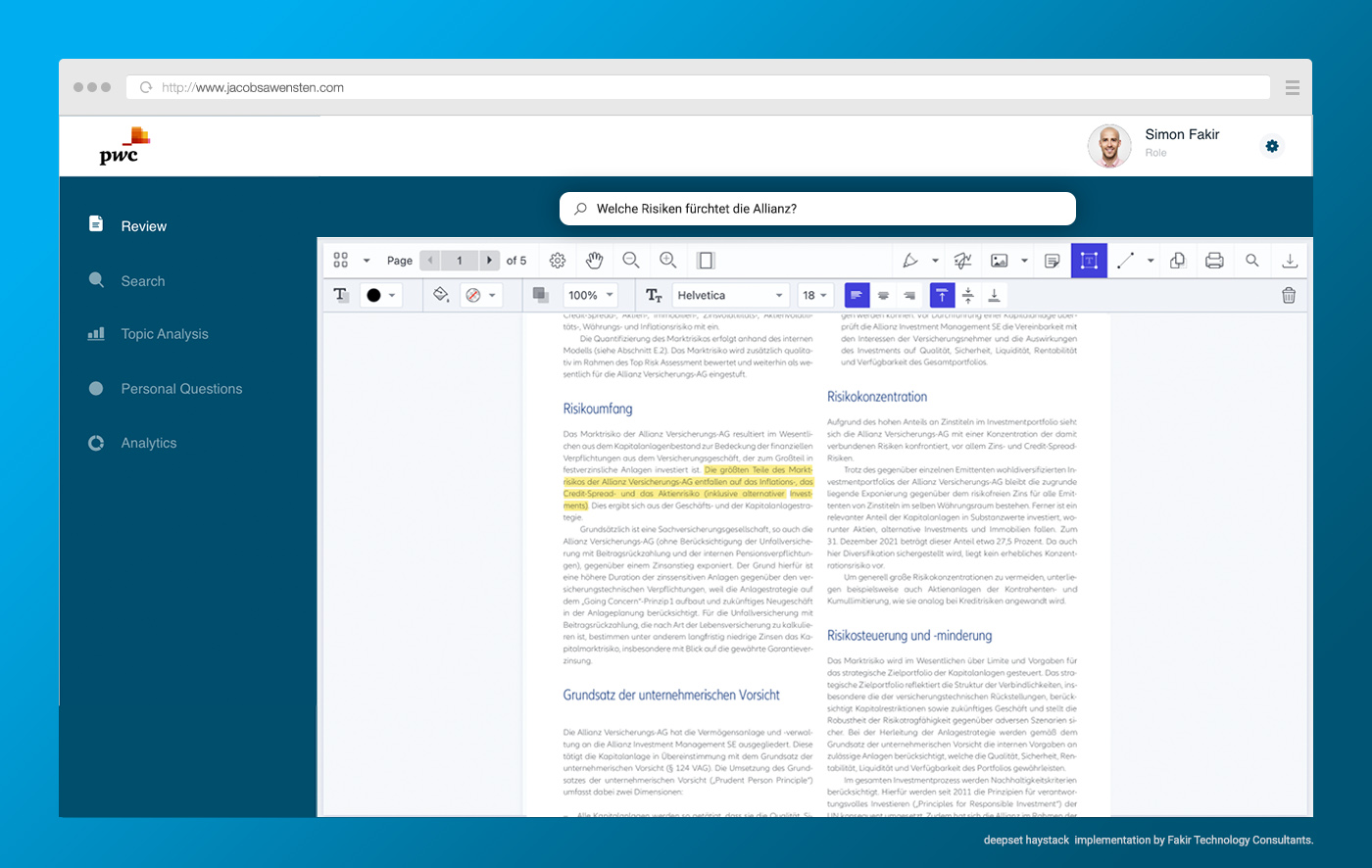
Im Rahmen eines unserer aktuellsten Projekte haben wir das Open-Source-Framework Haystack verwendet, um Information aus PDF-Dateien zu extrahieren. Die Anwendung zeigt dem Benutzer die PDF-Datei mit den extrahierten Informationen neben der ursprünglichen PDF-Datei an. Das ist ein sehr nutzerfreundlicher Weg, um die NLP-Technologie für den Endanwender einfach und gut nutzbar zu machen.
Auf dem Weg zur Entwicklung dieser Anwendungen haben wir eine Reihe von Herausforderungen gelöst. Die wir kurz hier kurz Vorstellen.
Überblick über die Herausforderungen bei Entwicklung gelöst:
- Extrahieren von Text aus PDF-Dateien
- Integration von Haystack
- Auffinden der Textposition in der PDF-Datei
- Anzeige des PDFs mit Hervorhebung im Browser
Im folgenden gehen wir durch die Herausforderungen Schritt für Schritt durch:
1) Extrahieren von Text aus PDF-Dateien
PDF ist ein ziemlich überfülltes Format. Bevor wir ins Detail gehen, möchte ich auf die folgenden Normen verweisen: PDF/A; PDF/X. usw. Die meisten computergenerierten PDF-Dokumente liegen in einer Vielzahl von PDF/A-Standards vor. Diese sind relativ gut strukturiert und können mit gängigen Java-Bibliotheken, wie Apache PDFBox, iText oder PDFtron, verarbeitet werden.
Der PDF A-Standard verlangt, dass das Dokument etwas verwendet, das “taggedPDF” oder “markedContent” genannt wird (was im Wesentlichen die gleiche Anforderung ist). Das bedeutet, dass jedes Element mit einem Inhalts-Tag versehen sein muss. Dies ermöglicht es Ihnen, Rauschdaten herauszufiltern und Text und andere Elemente zu erkennen. Wir können empfehlen, dies als Anforderung festzulegen.
| PDF Standard | Bedeutung | Erläuterung |
|---|---|---|
|
PDF/A |
A wie Archivierung |
PDF A wurde entwickelt, um Dokumente zu archivieren und ihre Verarbeitung durch Computer zu ermöglichen. Daher müssen sie den Rohtext enthalten. Scans – ohne OCR – sind nicht PDF-A-konform. |
|
PDF/A-1b |
B wie Basic |
PDF A1b nur auf die visuelle Reproduzierbarkeit abzielen. Sie haben also alles in sich, um sie ohne externe Abhängigkeiten lesen und betrachten zu können. Allerdings sind diese Dateien für unseren Anwendungsfall nicht hilfreich. |
|
PDF/A-1a |
Level A – accessible |
Gesucht ist der Zeitpunkt ‘PDF/A-1a’. Nach dem PDF-Standard ist der A-1a-Standard nicht nur visuell reproduzierbar, sondern er enthält auch Strukturinformationen über den Inhalt. Das wird uns bei der Verarbeitung helfen. Allerdings kann der A-1a-Standard bis heute nicht aus gescannten Dokumenten abgeleitet werden. |
|
PDF-A2;
PDF-A3;
PDF-A4 |
Extensions to PDF A1 |
Diese sind Erweiterungen des PDF-A-Standards und wurden später spezifiziert. Sie enthalten hauptsächlich neue Funktionen wie eingebettete Dateien und sind grundsätzlich auch kompatibel. Allerdings können diese Funktionen ihre eigenen Einschränkungen mit sich bringen (z. B. eingebettete Excel/Formulare usw.) |
|
PDF-X |
Print |
Dieser Standard ist nur für den Druck relevant. |
|
PDF-E |
Engineering |
Dies bezieht sich auf eine spezielle Norm für den technischen Bereich und ist hier nicht relevant. |
- Entfernung von Seitenzahlen oder “Rausch”-Daten
- Zeilenumbruch durch Bindestriche – in PDF ist das zum Beispiel “Techn-ology”, aber Sie wollen ja nur den Rohtext an Ihr NLP-System senden
- Sie könnten auch mit “vektorisiertem” Text konfrontiert werden, was bedeutet, dass der Text in Pfade umgewandelt wurde. Während dies im Druckbereich sehr typisch ist, sollte dies bei PDF-A-Dokumenten nicht der Fall sein.
Wir empfehlen, die taggedPDF-Parameter zu verwenden, um (1) zu lösen und Bindestriche durch Änderung der Y-Koordinate zwischen den markierten Inhaltselementen zu erkennen. Wenn Sie einen Beispiel-Quellcode benötigen, können Sie uns gerne kontaktieren.
2) Senden des Rohtextes an Haystack
Da haystack eine recht einfache API hat, war dies ein einfacher Prozess. Ich verweise auf die Haystack-API Dokumente für die spezifischen HTTP-Anfragen. Hier ist eine kurze Zusammenfassung, wie wir die Ausgabe verarbeiten:
Zunächst extrahieren wir die PDF-Datei und laden sie in Haystack hoch, sofern sie dort noch nicht vorhanden ist.
Zweitens: Abfrage von Haystack, um sicherzustellen, dass die Datei verarbeitet und einsatzbereit ist
Drittens wird der Datensatz mit bestimmten Filtern abgefragt, um nur Dokumente zu verarbeiten, die für uns relevant sind.
Bei diesem Schritt ist zu beachten, dass haystack ein paar Sekunden braucht, um Ihr Dokument nachzubearbeiten, bis es bereit zur Verarbeitung ist.
Die Schwierigkeit kommt im nächsten Schritt.
3) Finden der Textposition in Haystack

Wenn wir die Antwort von haystack erhalten, bekommen wir die Antwort als Zeichenkette, einschließlich eines Kontexts und des Dokumentnamens. Theoretisch sollte dies ausreichen, um die spezifische Position in der PDF-Datei zu finden.
Das Auffinden der Position war der schwierigste Teil, da der Text nachbearbeitet werden muss. Wir haben das Problem folgendermaßen gelöst:
- Wir sind alle markierten Inhaltselemente in der PDF-Datei durchgegangen und haben alle Sonderzeichen und alle Leerzeichen entfernt.
Bei den Leerzeichen gab es einige Probleme, die vom Verarbeitungs- und - Abstraktionsalgorithmus abhängen. Manchmal treten Leerzeichen auf, die dort nicht sein sollten.
- Wir haben die Rohzeichenketten, die wir von haystack erhalten haben, abgeglichen und uns die Anfangs- und Endposition im Originaldokument gemerkt.
- Anhand der Start- und Endposition berechneten wir die Rechtecke um den Text, um schließlich alles zu haben, was wir zum Hervorheben des Textes brauchen
Schließlich wurde das Rechteck ganz einfach in ein Format namens XFDF umgewandelt. Das XFDF-Format wurde für Formulardaten (in XML) entwickelt, enthält aber auch Hervorhebungen und Benachrichtigungen.
3) PDF im Browser darstellen
Als wir die letzte Aufgabe gelöst hatten, gab es viel Dankbarkeit und Freude darüber, dass die Ergebnisse endlich im Browser angezeigt werden.
Die Optionen zur Anzeige von PDFs im Browser sind die folgenden:
| Toolkit | Zusammenfassung |
|---|---|
|
PSDPDFKit commercial HQ: austria |
PSPDFKit is an austrian provider based on Googles Open Source PDF engine. They offer commercial support and we have experience using their system in production.
Drawbacks are in the details of slower loading times and a visually not appealing Search functionality. |
|
PDFTron commercial HQ: Canada |
PDFTron ist wahrscheinlich der “A-Player” auf dem Markt. Sie bieten einen Webviewer für PDF an, der Open-Source ist und auf React basiert. Allerdings ist der Preis auch recht hoch. |
|
Adobe PDF Embed API free-to-use HQ: San Jose |
Das Adobe-Produkt ist schnell, funktioniert gut, ist aber auch in seiner Funktionalität sehr eingeschränkt. Obwohl es kostenlos ist, ist der Dienst nur cloudbasiert und wir wissen weder, wie zuverlässig er langfristig ist, noch welche Daten in ihrem System übertragen und gespeichert werden.
Wir empfehlen diesen Ansatz für einen prototypischen Fall. |
|
Foxit PDF Viewer commercial HQ: ?, china |
Foxit ist wahrscheinlich eine gute Wahl in Bezug auf das Preis-Leistungs-Verhältnis. Aus unserer Erfahrung wissen wir jedoch, dass das technische Supportteam, das Ingenieurteam und wahrscheinlich auch der Hauptsitz in China angesiedelt sind. Für unsere Kunden war dies ein K.O.-Kriterium. Das Tooling ist jedoch in Ordnung, auch wenn die Dokumentation und die Beispiele schwieriger zu lesen und zu verstehen waren.
Wir würden diesen Fall empfehlen, wenn PSPDFKit oder PDFTron für Ihren Anwendungsfall zu teuer ist. |
|
PDF.js (express) open-source + fee HQ: Vancouver, CA |
PDF.js ist ein Open-Source-PDF-Viewer, der in vielen Fällen funktioniert. Unsere Tests haben jedoch ergeben, dass er bei größeren Dateien und vielen Elementen sehr schlecht abschneidet. PDF.js ist die einzige Engine, die vollständig auf Javascript (und nicht auf Webassembly) basiert und daher sehr langsam ist. Wir können weder PDF.js noch PDF.js express für professionelle Anwendungen empfehlen. Auch PDF.js express ist ein Service von PDFTron – wir vermuten, dass es hauptsächlich dazu dient, das Kernprodukt zu verkaufen. |
Im Grunde gibt es einen Kompromiss zwischen IT-Sicherheit, Vertraulichkeit und Kosten. Schließlich haben wir uns in einem Projekt für PSDPDFKit und in einem Pilotprojekt für “Adobe PDF embed” entschieden. Beide Tools waren in der Lage, alle Anforderungen zu erfüllen.
Zusammenfassung
Die Implementierung von NLP-Projekten mit PDF-Dateien ist keine einfache Aufgabe. Die Menge an Informationen, die in unstrukturiertem Text vorhanden ist bringt jedoch eine Menge Potential mit sich. Mit dieser Anwendung machen wir dieses Potential für Endanwender zugänglich und abstrahieren die gesamte Komplexität von PDF, NLP und der Verarbeitung von unstrukturiertem Text.
Wir sind stolz darauf, dass Tausende von Anwendern mit dieser neuen Technologie arbeiten und freue mich auf weitere Projekte.

Latest articles
- 03.11.2022
Tips for Managing Remote Employees
- 14.07.2019
Was macht ein CTO in einem Saas Start-Up?
- 05.10.2016