How to implement NLP based Textprocessing of PDFs using Haystack
As part of one of our recent projects, we used the Open Source Haystack framework to extract knowledge from PDF files. The resulting application shows the PDF file including the extracted information to the user, next to the original PDF file. That’s a great way to make the NLP technology easily and well-usable for end-users.
On the way of building these applications we solved a couple of challenges and to save you time, you can find our learnings here.
Overview of the challenges solved:
- Extracting Text from PDF files
- Integration of Haystack
- Finding the textposition in the PDF file
- Showing the PDF with highlight in the browser
1) Extracting Text from PDF files
PDF is a rather crowded format. Before we go into more details, I would like to refer to the following PDF/A; PDF/X. etc standards. Most computer-generated PDF documents are available in a variety of PDF/A standards. Those are relatively well structured and can be processed with common Java Libraries, like Apache PDFBox, iText, or PDFtron.
The PDF A standard requires the document to use something called “taggedPDF” or “markedContent” (which is essentially the same requirement). This means that each element needs to have a content tag. This allows you to filter out noise-data, and detect text and other elements. We can recommend setting this as a requirement.
| PDF Standard | Meaning | Purpose |
|---|---|---|
|
PDF/A |
A for archiving |
PDF A was designed to archive documents and to make it possible to process them by computers. Therefore they require to be contain the raw text. Scans - without OCR - are not PDF-A compliant. |
|
PDF/A-1b |
A1 b - basic |
PDF A1b to only focus on visual reproducability. So they have everything inside, to actually read and view them without external dependencies. However, these files are not helpful for our use-case. |
|
PDF/A-1a |
Level A - accessible |
The specific time 'PDF/A-1a' is the one we are looking for. According to the PDF standard the A-1a standard is not only visually reproducable, but it also contains structure information about the content. This will help us in processing. However, as of today A-1a standard cannot bebe derived from scanned documents. |
|
PDF-A2;
PDF-A3;
PDF-A4 |
Extensions to PDF A1 |
These are extensions to the PDF-A standard and specified later. They mainly contain new functionality like embedded files and are basically compatible as well. However, these features might bring their own limitations (e.g. embedded Excel/Forms etc.) |
|
PDF-X |
Print |
This standard is relevant for printing only. |
|
PDF-E |
Engineering |
This refers to a special standard for the engineering domain and is here not relevant. |
The extraction process itself is rather simple. However, some issues we faced were:
- Removal of page numbers or ‘noise’-data
- line-breaking hyphen – in PDF it’s for example “Techn-ology”, but you would only want to send the raw text to your NLP system
- You might also face ‘vectorized’ text, meaning that text was converted into pathes. While this is very typical in print-setup, it should not be the case in PDF-A documents.
We recommend to use the taggedPDF parameters to solve (1) and detect hyphens by Y coordinate change in between the marked Content Elements. If you need some sample sourcecode, feel free to contact us.
2) Sending the Rawtext to Haystack
Since haystack has a rather simple API, this was a simple process. I refer to the haystack API docs for the specific HTTP requests. Here is a quick summary of how we process the issue:
- First, we extracted the PDF and uploaded it to haystack unless it’s already there
- Second, we do query haystack to make sure the file is processed and ready to use
- Third, we query the dataset with specified filters to only process documents with relevance for us
In this step, please be aware that haystack needs a couple of seconds to post-process your document, until it’s ready to be processed.
The difficulty comes in the next step.
3) Finding the Text Position in Haystack

When we receive the response from haystack, we’ll receive the answer as string, including some context and the document name. In theory, this should be enough to find the specific position in the PDF file.
Finding the position was the hardest part, because of the post-processing of the text. Here is how we solved it:
- We went through all the marked Content Elements in the PDF file and removed all special characters and all spaces.
- On spaces we found a couple of issues, depending on the processing and abstraction algorithm. Sometimes spaces occur, which should not be there.
- We matched the raw strings, which we got from haystack and remembered the starting and end position in the original document.
- With the start and end position we calculated the rectangles around the text to finally have everything we need to highlight the text
Finally, the rectangle was very simple converted into a format called XFDF. The XFDF format was made for forms data (in XML), but also contains highlights and notifications.
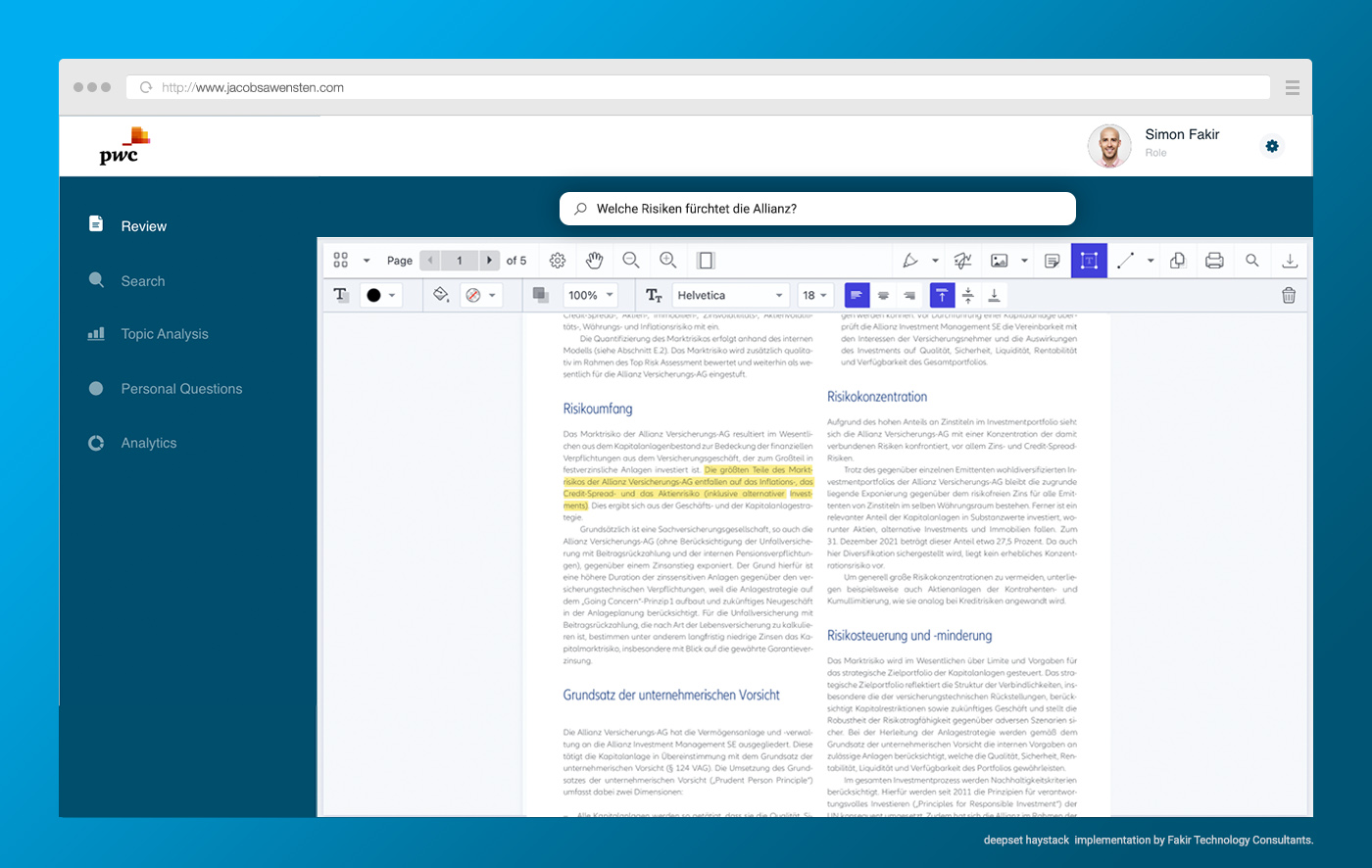
3) Show PDF in Browser
| Toolkit | Summary |
|---|---|
|
PSDPDFKit commercial HQ: austria |
PSPDFKit is an austrian provider based on Googles Open Source PDF engine. They offer commercial support and we have experience using their system in production.
Drawbacks are in the details of slower loading times and a visually not appealing Search functionality. |
|
PDFTron commercial HQ: Canada |
PDFTron is probably the 'A-player' in the market. They offer a webviewer of PDF, which is open-source and based on react. However, the pricing is also rather high. |
|
Adobe PDF Embed API free-to-use HQ: San Jose |
The Adobe product is fast, works well but is also very limited in functionality. Altough it's free, the service is cloud based only and we do not know about the long-term reliability nor do we know what data is transferred and saved in their system.
We recommend this approach for an prototype case. |
|
Foxit PDF Viewer commercial HQ: ?, china |
Foxit is probably a good price/value choice. However, we know from our experience that the technical support team, the engineering team and most probably also the headquarter is located in China. For our clients this was a knock-out criteria. However, the tooling is okay, even the documentation and examples were harder to read and understand.
We would recommend this case if PSPDFKit or PDFTron is too expensive for your use-case. |
|
PDF.js (express) open-source + fee HQ: Vancouver, CA |
PDF.js is one open source PDF viewer, which works in many cases. However, the learned from our tests that it performs very bad on larger files and many elements.
PDF.js is the only engine which runs completely on javascript (and not on webassembly) and therefore is very slow. We cannot recommend PDF.js nor PDF.js express for professional applications. Also PDF.js express is a service from PDFTron - We guess it's mainly made to upsell to their core-product. |
Basically, there is a trade-off between IT-Security, confidentiality, and costs. Finally, we chose PSDPDFKit in one project and ‘Adobe PDF embed’ in a pilot project. Both tools were capable of all the requirements.
Conclusion
Implementing NLP projects with raw PDF files is not a simple task. However, the amount of information available in unstructured text is huge, so it is it’s potential. With this application we make it easily accessible to end-users and abstract all the complexity of PDF, NLP and the processing of unstructured text.
We are proud to see thousands of users working with these new technology and I look personally forward what is going to come.
